본 논문은 CVPR 2019에 accepted된 논문이다.
1. Motivation
annotated trainind data를 모으는 것은 cost가 매우 많이 들기 때문에 이를 해결하기 위해서 Domain Adaptation (DA) method가 많이 제시되었었다. 특히 annotated 되지 않은 target domain이 train 때 접근 가능한 Unsupervised Domain Adaptation (UDA)에 대한 많은 연구가 이루어졌다.
대부분의 UDA method는 domain shift를 줄이는 방향으로 이루어졌는데, 직접적으로 source와 target marginal distribution을 align 시키는 방법으로 이루어졌었다. 이에 대한 방법으로 Correlation Alignment paradigm model domain data distribtuion에 대한 접근이 이루어졌었다. 이 때 soucre와 target domain의 covariance matrices 차이를 이용하게 되는데 이 때 covariance matrices는 network의 last-layer activation을 이용해서 얻는다. 두 matrices 사이의 차이에 해당하는 loss function을 minimize시키는 방식으로 source와 target domain을 match 하였다.
또 다른 UDA 방식에는 domain-specific alignment layers를 이용하는 방식이 있다. 이러한 방법에는 Batch Normalization (BN)이 존재한다.
본 논문에서는 두가지의 main novelties와 함께 기존의 paradigm들을 하나로 합치는 메소드를 제안한다.
- source와 target data distribution을 covariance matrices 를 이용해서 align시킨다.
- last-layer activation 에서 계산된 값으로 loss값을 계산하는 것이 아니라, domain-specific alignment layer를 이용한다. - intermediate feature들의 domain-specific covariance matrices를 이용한다.
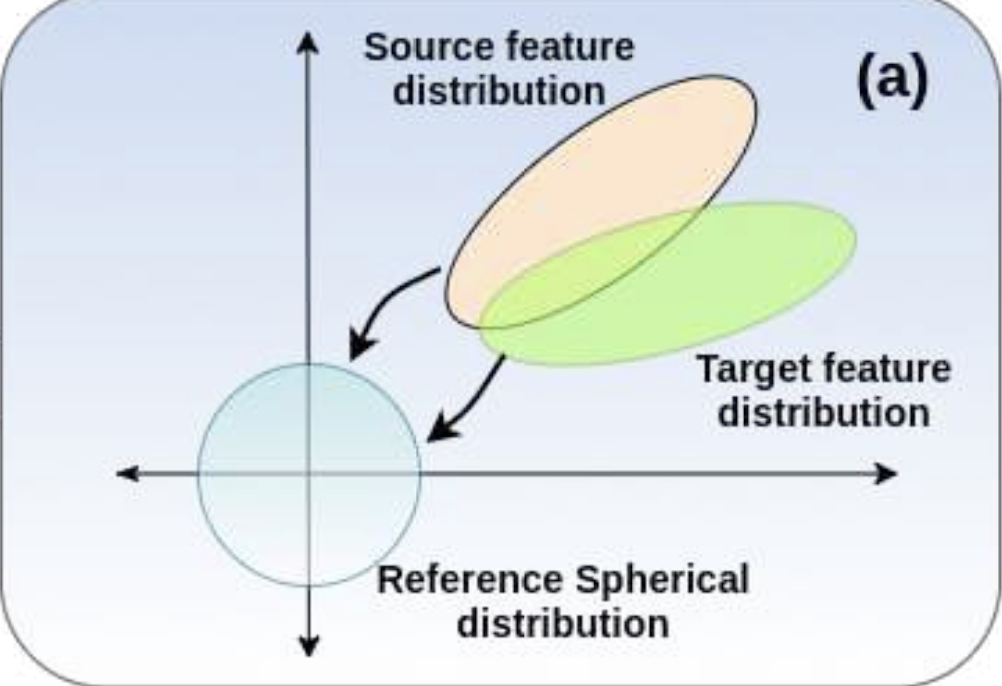
- 이 domain-specific alignment layer는 source와 target feature들을 “whiten” 시키고, 이 들을 common spherical distribution에 project한다.
- Domain-specific Whitening Transform (DWT)으로 부르며, 기존의 BN-based DA 기술들은 inter-feature correlations를 고려하지 않고, feature standardization 에만 의존했다면, 본 기술은 inter-feature correlation까지 고려하였다.
2. 새로운 loss function인 Min-Entropy Consensus (MEC) loss를 제안한다.
- entropy + consistency loss
- 이 loss는 너무 많은 hyper-parameter 튜닝을 해야하는 것을 막기 위해서 제시되었다.
- UDA의 경우에 target label이 존재하지 않기 때문에 hyper-parameter tuning이 매우 어렵다
- MEC loss를 제시 - 동일한 target sample로부터 나온 두 가지의 perturbed version의 coherent를 향상시키고, 이들의 prediction들을 pseudo label로 이용하였다.
2. Method
2.1. Preliminaries

UDA의 goal은 $\cal{S, T}$를 모두 이용해서 target domain에 대한 predictor를 배우는 것이다.
domain shift를 줄이기 위한 common technique는 BN-based layer들을 이용하는 것이다.
이 논문에서는 feature standardization 을 whitening으로 대체하였다. : whitening operation은 domain-specific하다.
<recap BN>

- i : mini-batch B안에 있는 x의 index
- k : data의 k-th dimension (1≤k≤d)
2.2. Domain-specific Whitening Transform
normalized되고 나서도 batch sample들은 아직 correlated feature value를 가지고 있다. 따라서 BN을 대체할 Batch Whitening을 제시하였다.


network는 input으로 다른 두 batch를 받게 된다. 각각 \cal{S, T}로부터 random하게 추출된 것이다. B^s=\{\bold{x^s_1, ..., x^s_m\}}, B^t=\{\bold{x^t_1, ..., x^t_m\}} 는 각각 batch of intermediate output activations를 의미한다.

W는 Cholesky decomposition을 통해서 계산된다. 이는 ZCA-base whitening보다 빠르다는 장점이 있다.
“coloring” step을 whitening 이후에 simel scale과 shift operation을 통해서 대체하였다.
feature grouping을 사용하였다. m(batch size)이 작고, d(dimension)가 클 때, batch-statistics estimate가 더 robust해지도록 하기 위해서 사용하였다.
학습하는 동안에, DWT layer는 target domain에 대한 statistics를 accumulate하고 이를 moving average로 이용한다.
2.2.1. Implementation Details
CNN의 Conv→ BN → ReLU를 Conv → DWT → ReLU로 변경하였다. source와 target feature를 projection하기 위해서 DWT layers는 full-feature whitening 을 계산하고 이 때 dxd whitening matrix를 이용한다. 이 때 d는 feature의 개수이다. 그러나, B의 covariance matrix를 계산하는 것은 d가 크고 m이 작을 때 매우 어려운 상황이 된다. 따라서 feature grouping을 이용한다. - feature들은 size가 g 인 group으로 나눠지게 된다.
2.3. Min-Entropy Consensus Loss
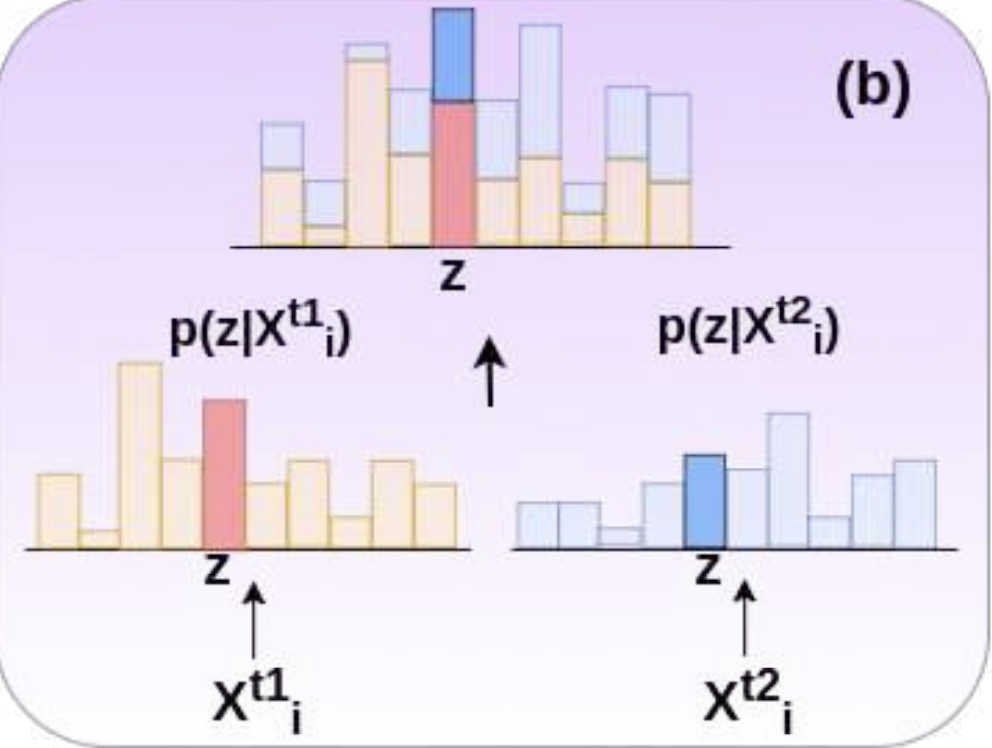
unlabeled target data를 잘 이용하기 위해서 새로운 loss를 도입하였다. consistency loss와 비슷하게 이 논문에서 제시하는 MEC loss는 input data perturbation을 요구한다. affine transformation과 gaussian blurring operation을 이용해서 data-perturbation을 적용하였다. MEC loss를 이용할 때 네트워크에는 3개의 batch가 들어가게 된다. source는 그대로 들어가고, target은 두가지의 다른 target batch가 들어가게 된다.
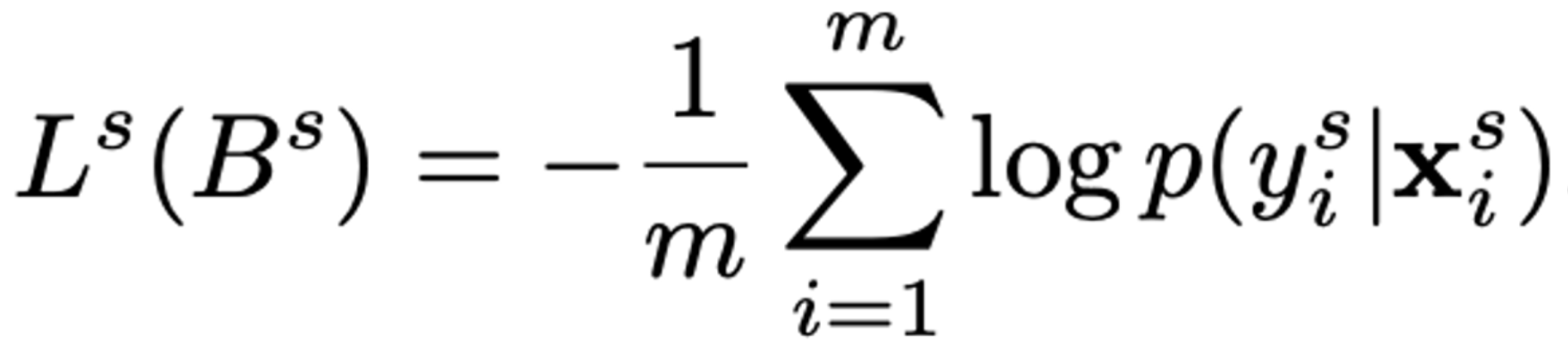
- source domain은 label을 가지고 있기 때문에 cross-entorpy loss를 적용한다.
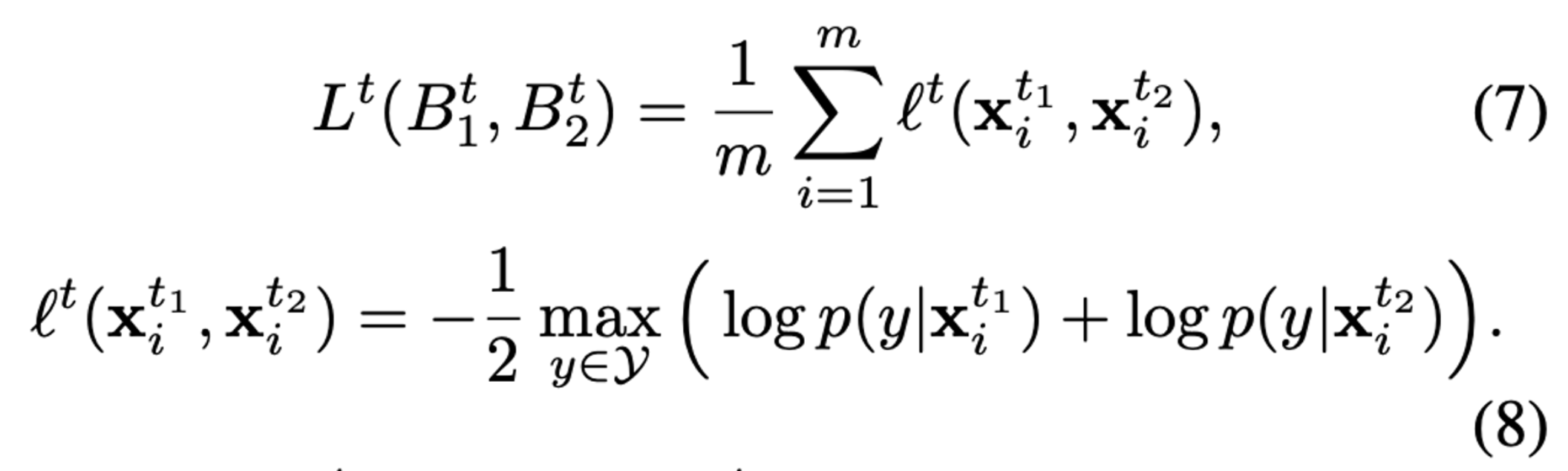
- target domain은 label이 없기 때문에 MEC loss를 적용한다. 각 class에 대한 p(y|x)둘을 계산하고 probability가 가장 큰 class 를 고르고 이를 loss로 적용하게 된다. x_t1과 x_t2는 같은 target domain으로부터 왔기 때문에 둘은 비슷한 prediction을 가져야 한다. 따라서 MEC loss는 아래 수식에 해당하는 class z를 찾게 된다. $z = {\rm{argmin}}_{y \in \cal{Y}} ({\rm{log}}\ p(y|\bold{x}_i^{t_1}) + {\rm{log}}\ p(y|\bold{x}_i^{t_2}) )$ 따라서 이 때 $z$는 $\rm{x^{t_1}_i}, \rm{x^{t_2}_i}$가 maximally agree인 class를 의미한다.
- → 이 $z$를 pseudo label로 이용한다.
- 이는 ad-hoc confidence thresholds 없이 select될 수 있는 pseudo label 이다. 즉, 해당 방법은 target sample과 관련이 적은 것을 버리는 방법이 아니라, 모든 sample들을 이용하고 z에 관한 backpropagation을 진행한다.
- MEC loss
- consistency loss와 비슷하게 이는 네트워크가 coherent predictions를 제공할 수 있도록 한다.
- consistency loss와 다르게 peaked predictions를 enforces한다. (consistency loss는 uniform posterior distribution에 해당하는 near zero value를 얻는 경향이 있다.)
따라서 최종 loss는 아래와 같다.
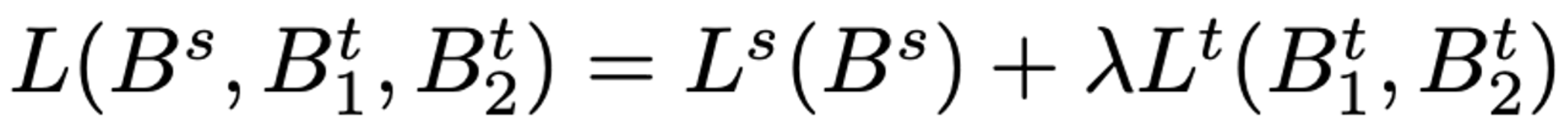
3. Experiments
3.1. Datasets
- MNIST ↔ USPS
- MNIST : 0부터 9까지의 handwritten grayscale image (28 x 28)
- USPS : MNIST와 비슷하지만 smaller resolution을 가지고 있다. (16 x 16)
- MNIST ↔ SVHN
- SVHN : Street View House Number image (32 x 32)
- MNIST와는 비슷하게 digits가 0부터 9까지이다. 하지만 SVHN images에는 variable oclor intensities를 가지고 있고, non-centered digits이기 때문에 MNIST와는 significant domain shift가 있다.
- SVHN : Street View House Number image (32 x 32)
- CIFAR-10 ↔ STL
- CIFAR-10 : 10 class dataset of RGB images (32 x 32)
- STL : CIFAR-10과는 비슷하지만 fewer labelled training images를 가지고 있다. (96 x 96)
- 두 데이터 상에서 겹치지 않는 class들은 제거되었다.
- Office-Home
- Office-Home 데이터는 4가지 domain을 가지고 있다. : Art, Clipart, Product, Real World
3.2. Experimental Setup
- Adap Optimizer
- 120 epochs
- 3가지 variants
- DWT layers w/o proposed MEC loss
- DWT-MEC
- DWT-MEC (MT) - DWT layers and the MEC loss in the Mean-Teacher (MT) training paradigm
3.3. Results
3.3.1. Ablation Study
- the impact of two main contributions:
- aligning source and target distributions by embedded DWT layers
- leveraging target data through threshold-free MEC loss
- SVHN → MNIST setting
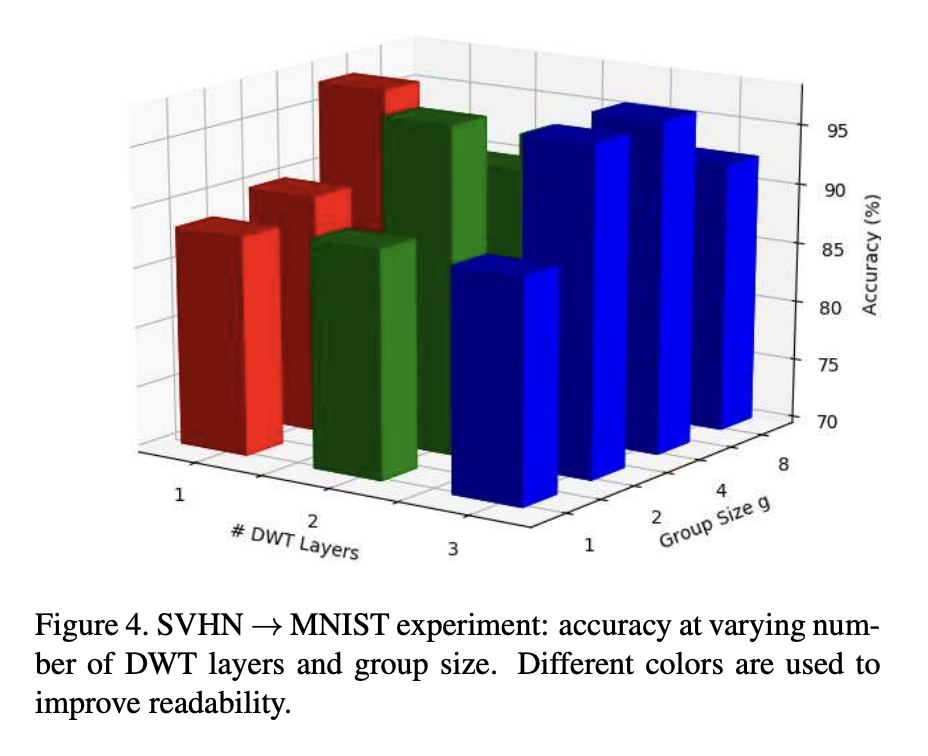
- BN보다 feature whitening의 benefit을 보여주었다. 1부터 3까지의 다양한 whitening layer와 group size g를 1부터 8까지 다양하게 변화해서 실험해보았다.
- group size = 1일 때 accuracy가 consistently 90%보다 낮았다. 이는 기존의 BN기반은 DA layer에서 achieved 되었던 source와 target domain data distribution이 sub-optimal에 빠졌다는 것을 말해준다.
- group size가 증가하면, feature decorrelation을 통해서 큰 성능 향상이 있었다
- g=4일 때 까지 성능 향상이 있었다. 그 이후는 아마도 covariance matrix 계산을 위한 ill-condition 때문이라고 생각했다.
- MEC loss의 effectiveness를 평가해보았다. Self-Ensembling (SE)를 이용했고, 이를 Confidence Thresholding(CT)를 이용했을 때와 이용하지 않았을 때의 성능을 비교해보았다.
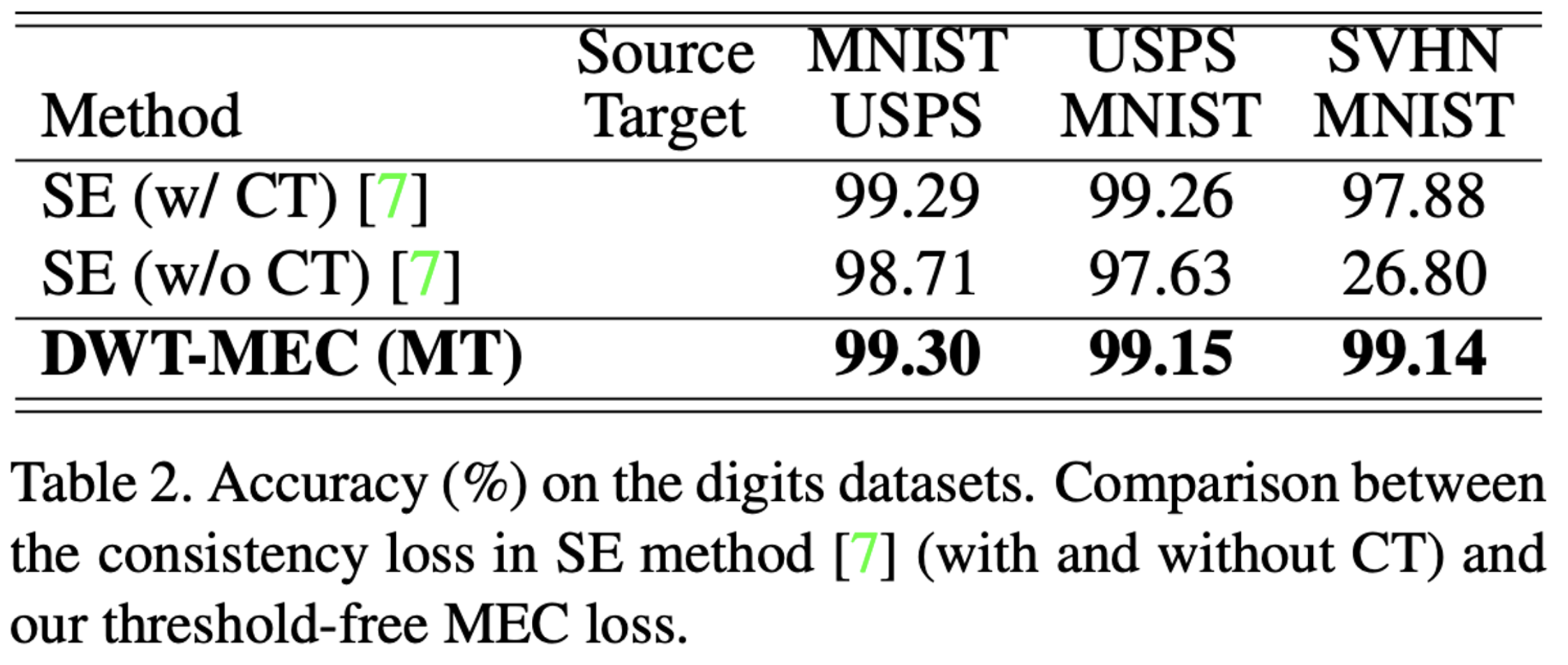
이 결과를 통해서 제안된 method는 CT hyper-parameter를 요구하지 않으며, 동시에 더 나은 성능을 보여주는 것을 알 수 있다.
3.3.2. Comparison with State-of-the-Art Methods
- 이전의 UDA methods들과의 비교를 진행해보았다.
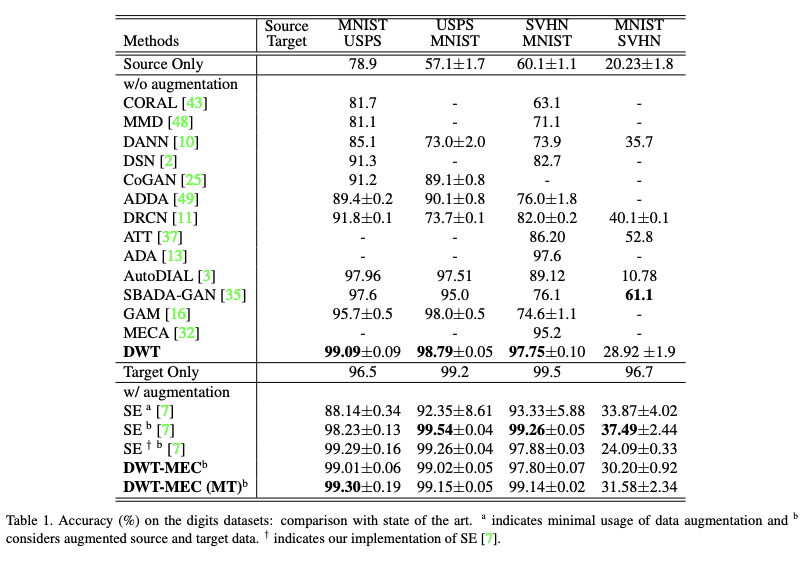
no-data augmentation method들과 비교했을 때, DWT이 더 좋은 성능을 보여주었다.
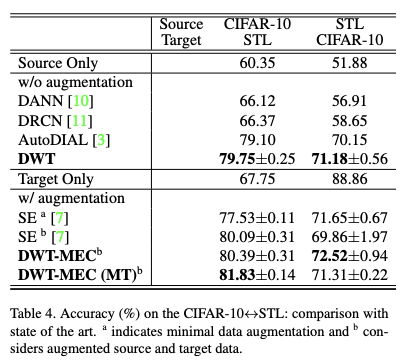
Table 4를 통해서 DWT가 기존의 모든 baselines들을 outperform 한 것을 알 수 있다. 더 나아가 data augmentation을 통해서 더 높은 성능을 달성하였다.
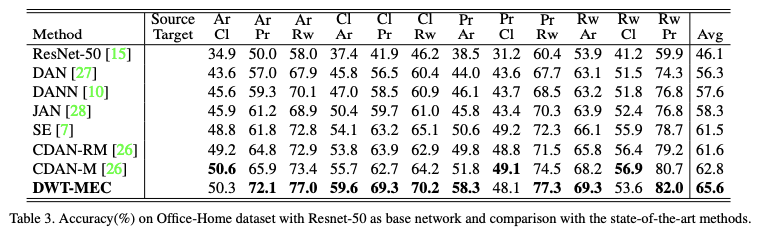
large scale dataset인 Office-Home에서 기존의 방법들과 비교했을 때 가장 높은 성능을 보이는 것을 알 수 있다.
4. Conclusions
whitening of intermediate feature를 통해서 source와 target domain을 align하였다. MEC loss가 target data를 exploit하기 더 좋다는 것을 보여주었다.