본 논문은 Semantic Correspondence와 관련된 논문으로, 이번 CVPR 2024에 채택된 논문이다.
저자: Junyi Zhang† Charles Herrmann‡ Junhwa Hur‡ Eric Chen§ Varun Jampani¶ Deqing Sun‡ * Ming-Hsuan Yang‡,§ ∗ †Shanghai Jiao Tong University ‡Google Research §UIUC ¶Stability AI §UC Merced
우선 본 논문은 semantic correspondence에 관한 논문이다. Semantic Correspondence란, 의미적으로 유사한 객체를 가진 두 이미지 간의 pixel 수준의 일치를 예측하는 분야로, 이미지 편집이나 style-transfer와 같은 Computer vision에서 중요한 분야로 다루어지고 있다.
1. Motivation
기존의 pre-trained large-scale vision model들은 semantic correspondence에서 좋은 성능을 보여주었으나, geometry나 orientation을 파악하는데 어려움을 겪었다는 것을 지적하며 논문이 시작되었다. 이를 바탕으로 이 논문은 semantic correspondence를 위하여 geometry-aware가 중요하다는 것을 강조하고있다.
우선 Stable Diffusion을 이용한 기존 SoTA인 방법에서, semantic 정보를 공유하지만, object에서 전반적인 geometry relation이 다른 경우 모델 성능이 크게 떨어지는 것을 발견하였다.

(a) 사진에서 볼 수 있듯이 'paw'라는 semantic 정보를 잘 읽었으나, "left paw", "right paw"와 같은 geometry 관계가 다른 경우, 잘 인지하지 못하는 것을 알 수 있었다.
빨간색 선이 잘못 match된 관계이며, 초록색이 옳게 match된 관계이다. 빨간 선을 확인해보면 고양이의 오른쪽 발임에도, 왼쪽 발과 연결된 것을 알 수 있다. 귀의 경우에도 왼쪽 고양이의 "오른쪽 귀"임에도, 오른쪽 고양이의 "왼쪽 귀"에 잘못 연결된 것을 알 수 있다.
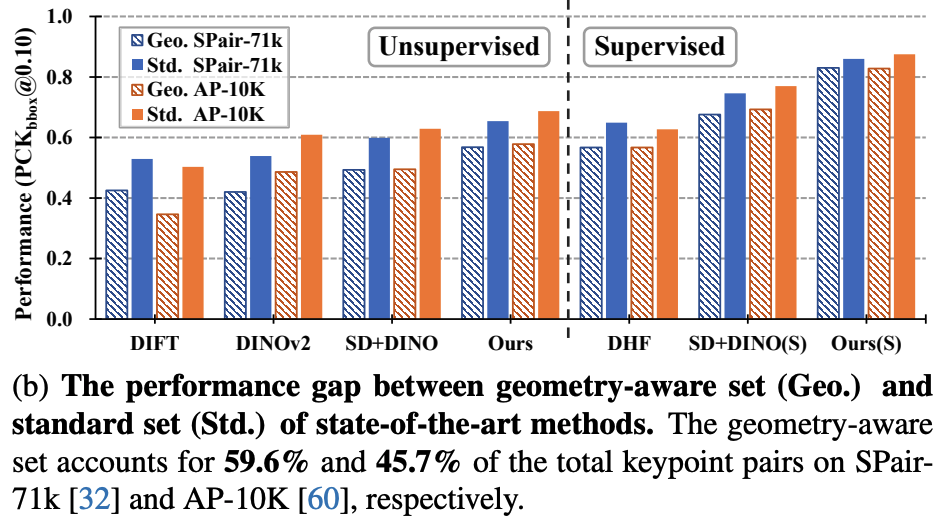
저자들은 이러한 분석을 바탕으로 더 깊은 분석을 진행해보았다. 그 결과, 위와 같은 경우가 벤치마크 데이터셋에서 상당한 비중을 차지했다는 것을 발견하였다. Spair71K 데이터셋의 경우에는 약 60%를 차지하고 있었다.
(b)는 geometry-aware set과 standard set에 대한 성능 차이를 보여주고 있다. geometry-aware set은 해당 논문에서 정의내린 subset으로, geometry-aware correspondence 케이스들을 모아놓은 쌍이다. 이는 뒤에서 더 자세하게 설명하고 있다.
논문의 앞파트에서는 이러한 geometry-set이 더 challenging한 subset이며, 실제로 기존 모델들이 standard set보다 geomtery-aware set에서 더 낮은 성능을 보인다는 것을 강조하고 있다.
따라서 이러한 관찰을 바탕으로 본 논문은 매칭 과정에서 geometrc ambiguity를 해결하기 위한 방법을 제안한다.
첫번째로, test time 때 object의 viewpoint를 align하는 방법을 제안하였다.
두번째로, sparse keypoint의 annotation을 활용하여 Visual Foundation Model에서 geometric awareness를 개선하는 방법을 제안하였다. 이는 soft-argmax를 기반으로 하였다.
또한 train과 test를 위한 대규모 벤치마크를 제안하였다.
2. Geometric Awareness of Deep Features
본 논문에서는 우선 "Geometry-Aware Semantic Correspondence"의 명확한 문제 정의를 하고있다. 이는 앞의 motivation에서 설명했듯이 "왼쪽 발"과 "오른쪽 발"과 같이 기하학적으로 다른 위치에 있는 유사한 부분의 relation을 잘 파악해야하는 task이다.
2.1. Geometry-Aware Semantic Correspondence
Geometry-Aware Semantic Correspondence의 경우 객체의 방향이나 기하학적 구조를 더 이해해야한다.
Formal Definition에 따르면, 각 instance category마다, keypoint를 semantic part에 따라 여러 subgroups로 나누게 된다.
이 subgroups들은 keypoint들로 이루어져있으며, keypoint들은 $\bold{p}_{(parts, index)}$ 로 표현된다.
Gpaws = {p(paws, front left) , p(paws, front right) , p(paws, rear left) , p(paws, rear right)}
위와 같이 paws라는 subgroup안에 keypoint들이 존재하며 이는 해당 subgroup의 parts와 front left와 같은 geometric index로 구분되어있다.
즉 '고양이'라는 instance category안에는 'paws', 'ears'와 같은 subgroup들이 있으며, G_paws와 같은 paws subgroup 안에는 'front left paws', 'front right paws' 등의 keypoint들로 구성되어 있는 것이다.
이후 Source Image와 동일하거나 비슷한 instance catgegory를 포함하는 Target이미지가 주어진다.
이 이미지에는 keypoint correspondence annotation이 주어진다.
이 때 두 가지 조건이 충족되면 해당 Matching을 "geometry-aware correspondence"로 간주하게 된다.
1. 두 keypoint가 같은 subgroup에 속해야한다. 즉 고양이라면 source와 target 이미지의 keypoint가 모두 고양이의 발, 고양이의 귀 등 같은 subgroup이어야한다.
2. Target 이미지에는 동일한 subgroup에 속하는 다른 keypoint가 있어야 한다. 이는 다른 keypoint가 존재해야 geometric하게 구분해야할 요소가 있는 것이기 때문에 필요한 조건이다. 같은 subgroup에 속하는 다른 Keypoint가 없는 경우에는 기하학적 혼동이 발생할 가능성이 없기 때문이다. 즉, 예를 들어 고양이의 배에 Keypoint가 source와 target image가 있다고 가정한다면, 이 두 Keypoint에 대한 matching은 Geometric-aware correspondence로 간주될 필요가 없다. 발은 왼쪽발, 오른쪽 발 등 기하학적으로 구분해야하는 경우가 생기지만, 배에 하나의 keypoint가 있으면 기하학적으로 구분할 필요조차 없기 때문이다.
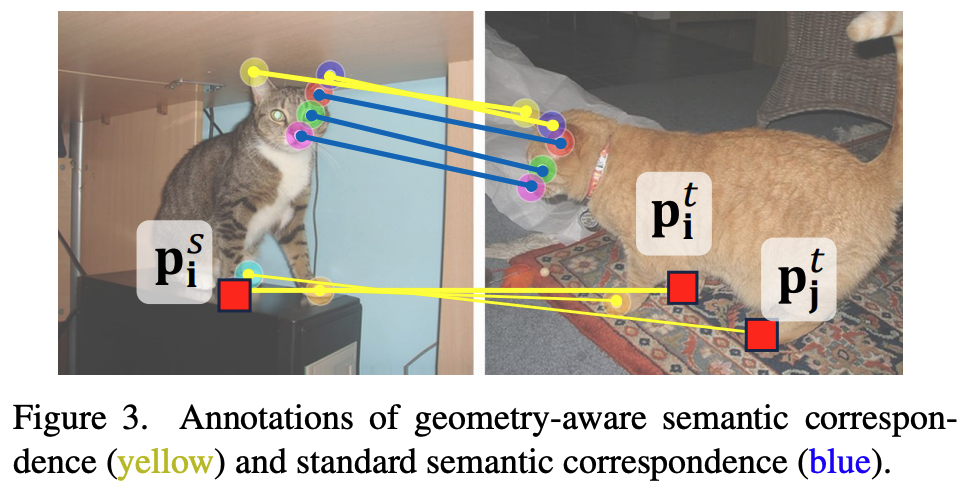
Figure 3에서 geometry-aware correspondence를 확인할 수 있다.
왼쪽은 source image이고 오른쪽은 target image이다. source image의 keypoint인 $p^S_i$에 대해 target image의 keypoint인 $p^t_i$가 같은 subgroup인 paws에 속해 있어서 1번을 만족한다.
이 때, 동일한 Subgroup인 paws에 속하는 또다른 keypoint인 $p^t_j$가 존재한다.
따라서 $p^S_i$와 $p^t_i$는 Geometric-aware Correspondence이다.
2.2. Evaluation on the Geometry-aware Subset
해당 파트에서는 geometry-aware semantic correspondence에서 최신 방법들이 얼마나 좋은 성능을 보이는지 확인해보았다.
SPair-71K dataset에서 각 category의 keypoint들을 subgroup으로 클러스터링하고, 위에서 언급한 geometry-aware correspondence case들을 모아서 "geometry-aware subset"을 만들었다.
이 geometry-aware subset들은 데이터셋의 상당한 부분을 차지하고 있었다. 전체 이미지쌍의 82.4%를 차지했으며, matching keypoints중 59.6%를 차지하였다.
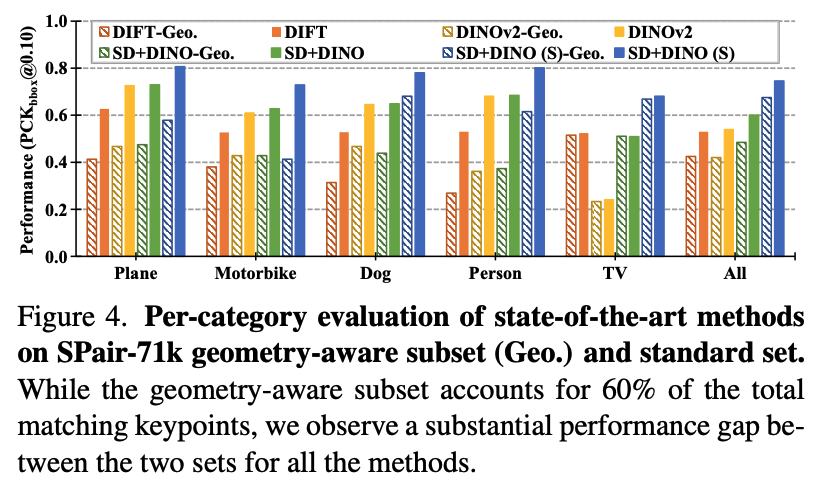
Figure 4는 SPair-71K dataset에서 geometry-aware subset에 대한 성능을 보여주고 있다.
성능은 PCK(Percentage of Correct Keypoints)로 측정하였으며, geometry-aware subset의 성능은 standard set에 비해 낮은 성능을 보여주었다. Zero-Shot의 경우 약 20%의 성능 차이가 있었으며, Supervised 방식에서도 10%의 성능 차이가 났다.
2.3. Sensitivity to Pose Variation
Figure 4에서 geometry-aware subset과 standard set이 성능차이를 보였으나, 특정 몇몇 category에 대해서는 성능 차이가 거의 없는 경우도 있었다. SPair-71k dataset에서는 TV나 potted plant가 거의 성능 차이가 없었다.
이는 Pose의 변화가 geometry-aware correspondence의 정확성에 영향을 크게 미친다는 것을 알려준다.
따라서 이를 더 깊게 분석하기 위해서 본 논문은 azimuth difference(방위각 차이)에 따라 이미지의 쌍을 5개의 subset으로 나누었다.
포즈 차이가 없는 경우(0)부터, 완전히 반대 방향(4)까지 총 5개이며, A={a0,a1,…,a4} 이 하위집합에서 다시 성능을 평가해보았다.
예를 들어 고양이의 이미지 쌍인 경우, 고양이가 거의 동일한 포즈를 하고 있는 경우(0)에서 부터, 완전히 반대방향을 보고 있는 경우(4)로 나눈 것 같다. 그런데 총 5개로 정확히 어떤 기준의 pose로 구분된 것인지는 모호하다...
아무튼 나눠진 subset을 기반으로, performance를 측정하고, normalized relative difference인 d를 아래와 같은 수식으로 측정한다.
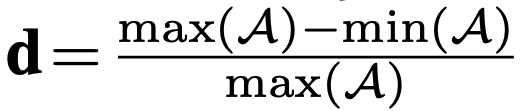
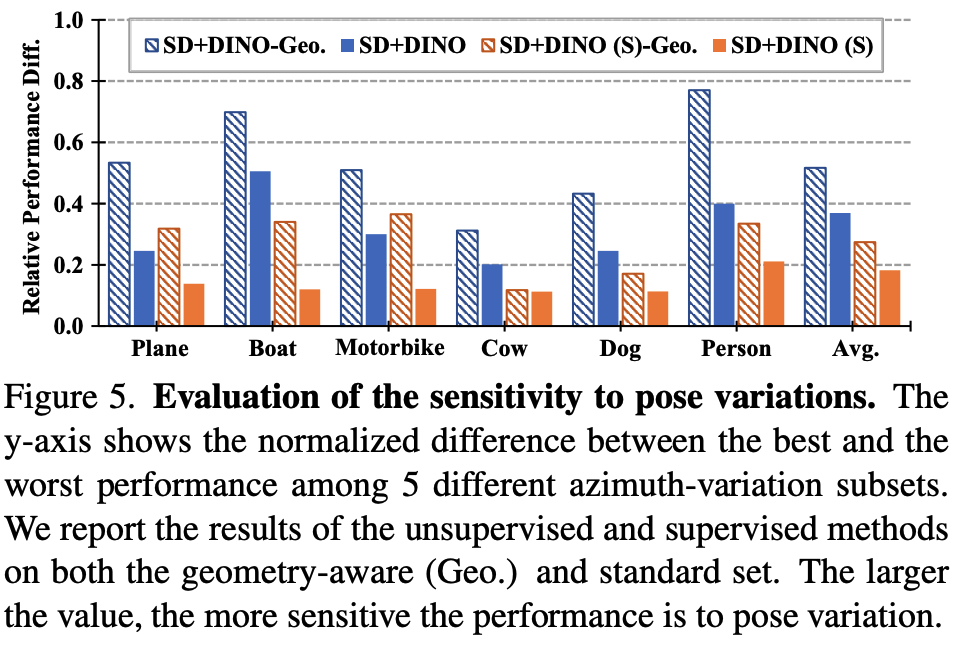
Figure 5에서 보았을 때, geometry-aware subset의 성능이 relative performance difference가 더 큰 것을 알 수 있다. 이는 geometry-aware subset이 standard set보다 pose variation에 더 민감하게 반응한다는 것을 보여주며, pose variation이 semantic correspondence의 성능에 영향을 미친다는 것을 보여준다.
2.4. Global Pose Awareness of Deep Features
이 파트에서는 Deep Feature가 high-level pose information을 인식하는지에 대한 분석을 하였다.
우선 pose 예측의 정확도를 평가하기 위해서 새로운 Instance Mathcning Distance (IMD)를 도입하였다.
해당 metric은 source image, target image, 그리고 이들의 normalized feature maps (F)와 source instance mask M이 있을 때 아래와 같이 정의된다.
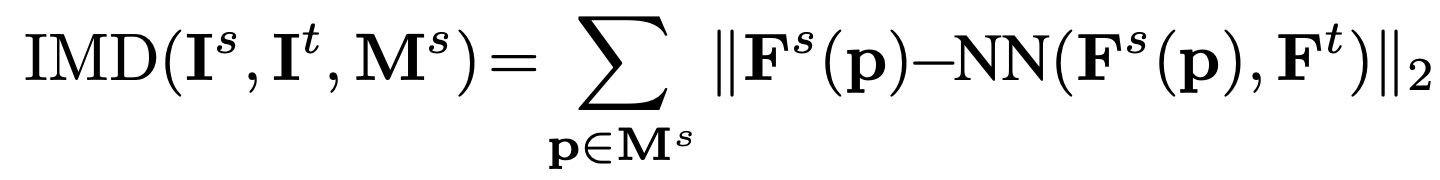
p는 source instance mask M 내의 pixel을 의미하며, $F^s(p)$ 는 해당 pixel에서의 feature vector이고, NN은 target feature map에서 Nearest-Neighboring feature vector를 의미한다.
IMD는 두 이미지의 average feature distance를 의미하게 된다.

IMD를 이용해서 기존 방법들의 global pose wareness를 측정해보았다. 여러 pose template set들을 생성하고, input image에 대해 template image와의 IMD를 계산하여 IMD가 가장 작은 pose를 예측하게 된다.
저자들은 SPair-71K dataset의 100개의 cat image들에 대해 {left, right, frong, and back}으로 annotate하였고, 이를 이용해서 pose prediction을 평가하였다.
annotation을 할 때 모호한 경우가 있기 때문에 {left, right}, {fron, back}으로 되어있는 binary classification 성능도 report하였다고 한다.
기존의 기술들이었던 DINOv2, SD, SD+DINO에 대해서 성능 평가했다.
즉, DINOv2, SD, SD+DINO의 feature들의 matching distance를 뽑아내고, 가장 낮은 IMD를 가진 pose를 예측 결과물로 내게 된다. 이를 annotation한 pose label과 비교하여 얼마나 예측이 정확한지에 대한 성능을 평가하였다. 즉, 각 모델의 feature를 IMD를 이용하여 pose prediction을 했을 때의 정확도를 나타내었다. 해당 결과가 Table 1에 나와있다.
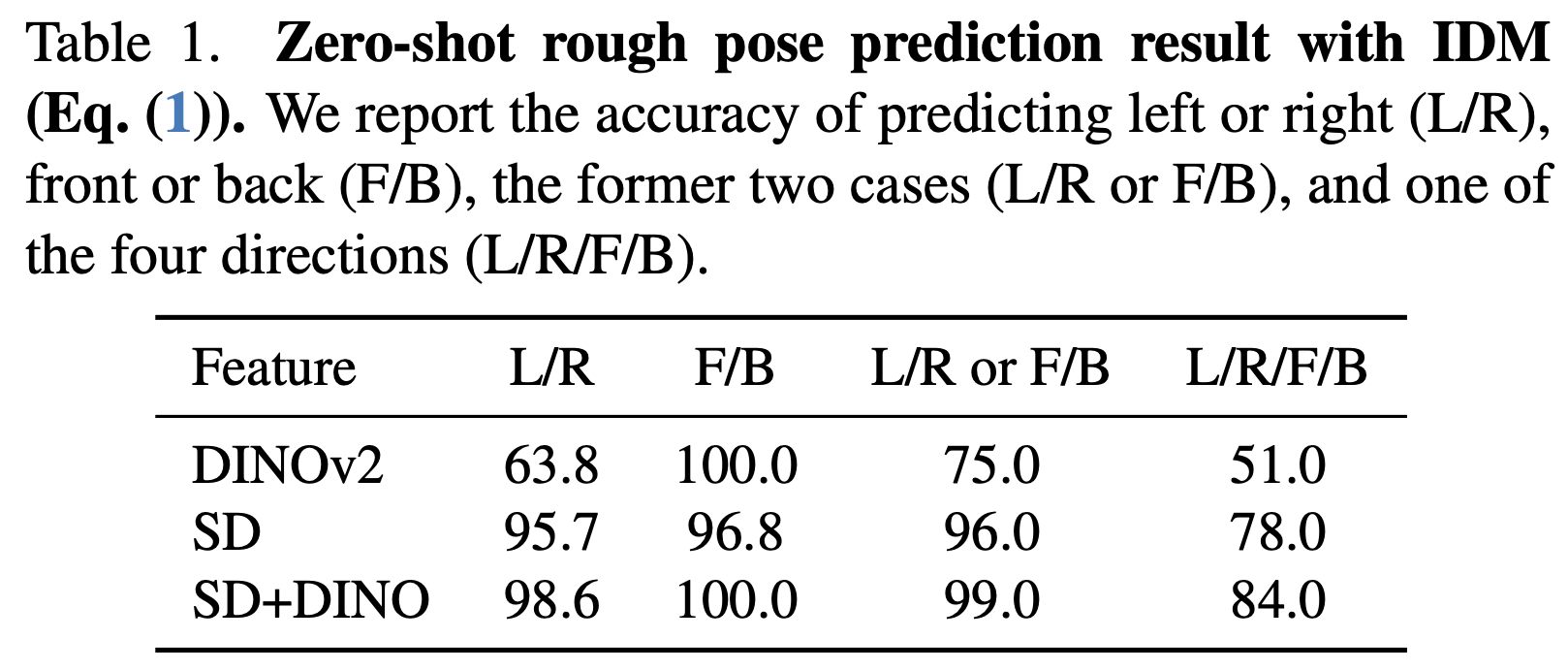
SD+DINO의 경우 대부분의 경우에서 좋은 결과를 달성하였으며, 이를 통해 SD+DINO에서의 deep feature가 global pose awareness가 좋다는 것을 보였다.
3. Improving Geo-Aware Correspondence
위에서는 geometry-aware correspondence가 중요하며, 특히 pose가 이에 많은 영향을 준다는 것을 알아내었다.
따라서 이 파트에서는 geo-aware correspondence를 개선하기 위한 몇가지 방법을 제안하였다.
Zero-Shot및 Supervised 에서 macthing 성능을 높이는 것을 목표로 한다.
3.1. Test-time Adaptive Pose Alignment
앞선 내용에서 pose 의 변화가 geometry-aware에 매우 중요한 영향을 준다는 것을 밝혀내었다. 따라서 이를 바탕으로 test 때 deep feature안에 내재되어있는 global pose information을 이용하여 pose를 align시키는 것을 제안하다.
1. source image에 대해 여러 pose-variance augmentation (flip, rotation)을 적용하여 image augmentation을 한다.
2. augment된 source image와 target image 사이의 IMD를 계산한다.
3. IMD가 가장 작은 pose를 선택한다.
이 가장 작은 pose가 사실상 source image 대신에 사용되는 것이다.


Figure 9에서 볼 수 있듯이, 왼쪽은 original image pair이고, 오른쪽은 test-time aligned pose인데, target image에 맞게 pose가 변경된 경우 align이 더 잘 된 것을 알 수 있다.
3.2. Dense Training Objective
기존의 방식들은 제한된 keypoint pairs에 대해서만 학습을 진행하는 sparse training을 적용하였다.
CLIP-style symmetric contrastive loss 를 이용해서 pose-processed source 와 target feature의 keypoints들에 대해서 loss를 적용한다.

def cal_clip_loss(image_features, text_features, logit_scale, self_logit_scale = None):
total_loss = 0
device = image_features.device
logits_per_image, logits_per_text = get_logits(image_features, text_features, logit_scale)
labels = torch.arange(logits_per_image.shape[0], device=device, dtype=torch.long)
total_loss += (
F.cross_entropy(logits_per_image, labels) +
F.cross_entropy(logits_per_text, labels)
) / 2
return total_loss
loss 수식에 대한 구체적인 수식이 없어서 코드를 찾아보았다.
CLIP에서 사용한 것 과 같이 image와 text의 대응관계를 학습하는데, 이 논문에서는 image와 text 대신 source image와 target image가 사용되는 것이다.
그러나 이 loss는 keypoint로만 loss가 적용되기 때문에 이외의 유용한 정보가 사라질 수 있다. 따라서 본 논문에서는 Dense loss를 추가하였다.
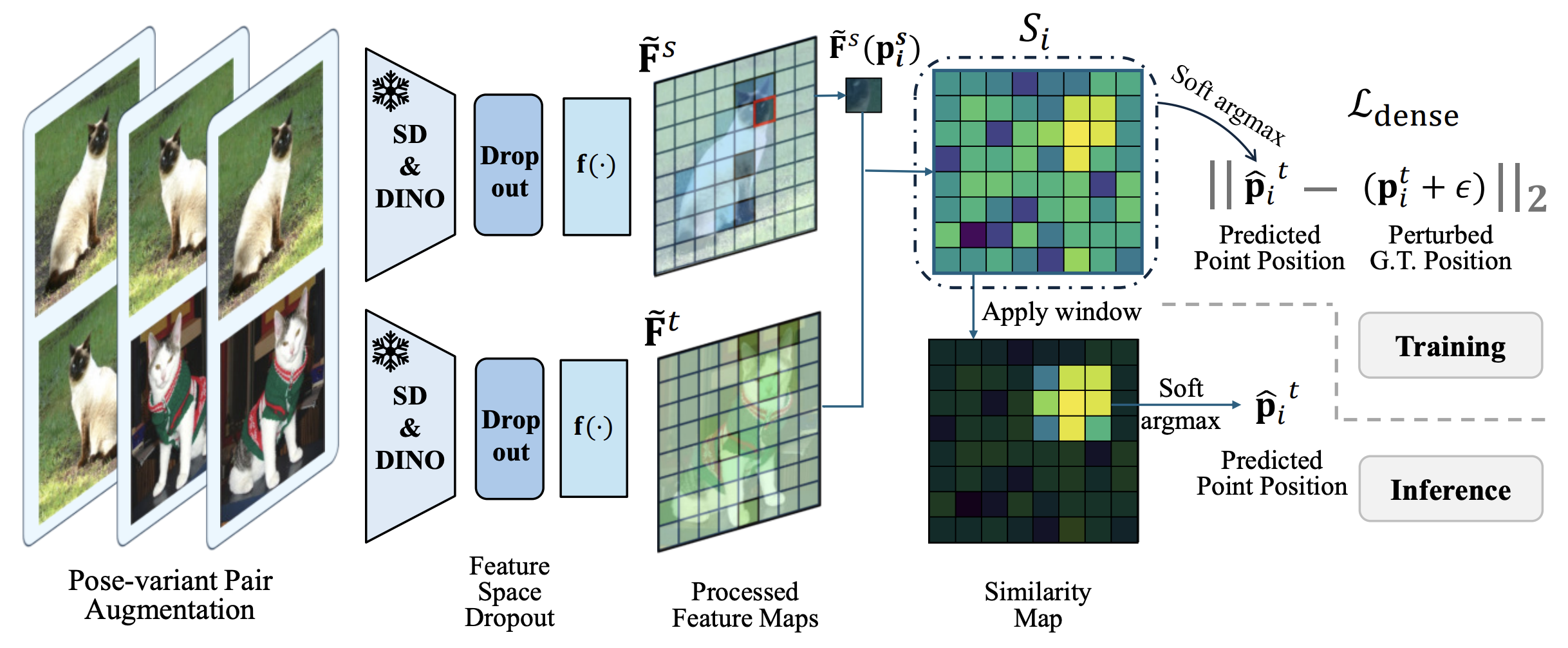
우선 여기서는 Similarity map을 계산한다.
source image의 keypoint에 대한 feature vector와 target image의 feaeture map 전체에 대한 similarity map을 계산하게 된다.
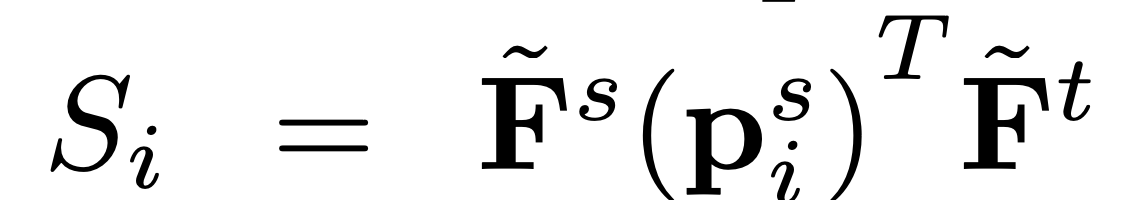
이후 soft-argmax를 이용하여 predicted point position을 뽑아낸다.
즉 이는 source image의 keypoint에 대응되는 target point를 찾아낸 것이다.
이후 실제 target keypoint와 L2 loss를 적용하여 가깝게 만들고, 이 때 가우시안 노이즈를 추가로 주어서 overfitting을 방지하였다.
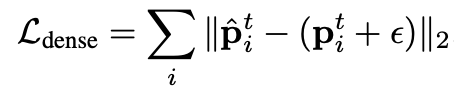
3.3. Pose-variant Augmentation
기존의 data audmgnetaion의 경우 computation cost가 증가하고, pose 변형 관점에서는 부족하다는 단점이 있다고 지적하고 있다. 즉 copping, scaling등은 다른 pose를 제공해주지 못한다.
따라서, 본 section에서는 pose-varying augmentation을 제안한다. 저자들은 이미 deep feature들이 전반적인 pose의 정보를 인식하고 있기 때문에 pose가 달라진 feature map이 모델에 새로운 signal을 제공해줄 수 있다고 주장한다. 이러한 점에서 feature map을 augmenation 시키는 것이 아니라 image 자체를 augmenation시킨다.
3가지 augmentation setting을 제시하였다.
1) double flip: source image와 target image를 모두 flip시킨다.
2) single flip: source image만 flip 시키고, target image는 원본을 유지한다.
3) self flip: source image와 flipped source image를 사용한다.
이 때 2,3의 경우에는 keypoint annotation또한 flip된다. 예를들어 self flip의 paw의 경우로 생각했을 때 original source image에서 left paw라면, flipped source image의 경우에는 right paw가 되어야한다.
왜 double flip은 annotation을 flip 시키지 않는지에 대한 의문이 들었었는데, 어차피 둘의 관계가 중요한 것이기 때문에 두 이미지 중 한 이미지만 flip된 경우에만 서로의 correspondence가 변화되고, 이 경우에만 annotation flip이 필요한 것이었다.
3.4. Window Soft Argmax
기존의 연구들은 similarity map에서 correspondence를 추론할 때 Argmax를 이용한다. 이는 similarity map에서 가장 큰 값을 가지는 pixel을 선택하는 방식이다. 그러나 이 방법에는 두가지 단점이 있다고 지적한다.
1) sub-pixel 수준의 inference가 불가능하다는 것이다. argmax는 정수 좌표의 pixel만을 선택할 수 있다는 점에서 단점이 있다는 것이다.
2) argmax는 선택된 pixel의 주변 pixel들의 정보를 고려하지 않고 단순히 최대값을 뽑기 때문에 spatial context를 고려하지 못한다는 단점이 있다는 것이다.
이를 해결하기 위해서 일부 연구에서는 Soft-Argmax를 사용하였다. Soft-Argmax는 각 pixel의 유사도를 바탕으로 가중 평균을 계산하는 것이다. 그러나 이는 모든 pixel의 유사도를 고려하기 때문에 noisy할 수 있다는 단점이 있고, 실제로 뒤에서 언급할 실험 결과에서 성능 향상이 없었다고 말한다.
따라서 본 논문에서는 Window Soft Argmax를 제안한다.
우선 Argmax연산을 통해서 simailirity map에서 유사도가 가장 높은 pixel 좌표를 선택한다. 이 후, 선택된 pixel을 중심으로 사전에 정의된 window를 설정하고, 해당 window 안에서만 soft-argmax를 적용한다.
뒤에도 언급하겠지만, 실제로 Window Soft Argmax를 사용했을 때 성능향상이 있었다고 한다.
4. Experimental Results
Implementation details
SD와 DINOv2를 통해서 feature를 뽑아내기 위해서 input image를 960x960, 840x840으로 resize하였다. 이를 통해서 60x60 resolution의 feature map을 얻었다.
논문에서 f(.)로 표시된 post-processor는 raw feature map을 refined feature map을 내보내주는 역할을 하며, 이는 four bottleneck layers로 구성되어있다.
해당 부분을 코드로 찾아보았다.
def get_processed_features(sd_model, sd_aug, aggre_net, extractor_vit, num_patches, img=None, img_path=None):
if img_path is not None:
feature_base = img_path.replace('JPEGImages', 'features').replace('.jpg', '')
sd_path = f"{feature_base}_sd.pt"
dino_path = f"{feature_base}_dino.pt"
# extract stable diffusion features
if img_path is not None and os.path.exists(sd_path):
features_sd = torch.load(sd_path)
for k in features_sd:
features_sd[k] = features_sd[k].to('cuda')
else:
if img is None: img = Image.open(img_path).convert('RGB')
img_sd_input = resize(img, target_res=num_patches*16, resize=True, to_pil=True)
features_sd = process_features_and_mask(sd_model, sd_aug, img_sd_input, mask=False, raw=True)
del features_sd['s2']
# extract dinov2 features
if img_path is not None and os.path.exists(dino_path):
features_dino = torch.load(dino_path)
else:
if img is None: img = Image.open(img_path).convert('RGB')
img_dino_input = resize(img, target_res=num_patches*14, resize=True, to_pil=True)
img_batch = extractor_vit.preprocess_pil(img_dino_input)
features_dino = extractor_vit.extract_descriptors(img_batch.cuda(), layer=11, facet='token').permute(0, 1, 3, 2).reshape(1, -1, num_patches, num_patches)
desc_gathered = torch.cat([
features_sd['s3'],
F.interpolate(features_sd['s4'], size=(num_patches, num_patches), mode='bilinear', align_corners=False),
F.interpolate(features_sd['s5'], size=(num_patches, num_patches), mode='bilinear', align_corners=False),
features_dino
], dim=1)
desc = aggre_net(desc_gathered) # 1, 768, 60, 60
# normalize the descriptors
norms_desc = torch.linalg.norm(desc, dim=1, keepdim=True)
desc = desc / (norms_desc + 1e-8)
return desc
논문에서 표시한 raw feature가 desc_gathered 같다. 이는 stable diffusion에서 추출한 feature와 dinov2에서 추출한 feautre들이 결합되어있다.
aggre_net이 논문에서 말한 post-processor같다. 이는 desc_gathered를 input으로 받아서 refined feature를 내보내게 된다.
Datasets
많이 사용되는 PF-Pascal, SPair-17k를 데이터셋으로 이용했고, 새롭게 benchmark를 제안하였다.
- PF-Pascal
- 2,941 training, 308 validation, 299 testing image pairs with similar viewpoints and instance pose
- 20 categories
- Spair-71k
- more challenging and larger-scale dataset
- 53,340 training pairs, 5,384 validation pairs, and 12,234 testing pairs
- 18 categories
- AP-10K Benchmark
- 저자들이 새롭게 제시한 동문의 pose 추정 dataset이다.
- 23개 families에 속하는 54개 종 동물을 포함한 10,015개 이미지로 구성되어 있다.
- 각 이미지당 17 keypoints가 annotation 되어 있다.
- 이미지 중 여러개의 instance를 포함하거나, 3개 미만의 visible keypoint가 있는 이미지는 제거하였다.
- 총 261,000개의 training, 17,000개의 validation, 36,000개의 test 쌍으로 구성되었다. 각 이미지가 여러 이미지들과 조합에서 쌍을 이룰 수 있기 때문에 이미지보다 쌍의 개수가 훨씬 많을 수 있는 상황이다.
- validation과 test image는 3가지 setting으로 구성되어 있다: Intra-species set, Cross-species set, Cross-family set이다.
Evaluation metrics
Percentage of Correct Keypoints (PCK)으로 평가하였다. 이는 keypoint의 위치를 얼마나 정확히 예측하는가에 대한 평가를 하며, 해당 keypoint가 정해진 threshold안에 존재할 경우, 정확하게 예측한 것으로 간주되며, threshold는 $\alpha ma(h,w)$로 결정된다. alpha는 소수값이고 (e.g. 0.10), h와 w는 Spair-71k와 AP-10K에서는 object의 bounding box의 높이와 너비이고, PF-Pascal에서는 이미지 자체의 크기가 이용된다.
4.1. Quantitative Analysis
Overall semantic correspondence
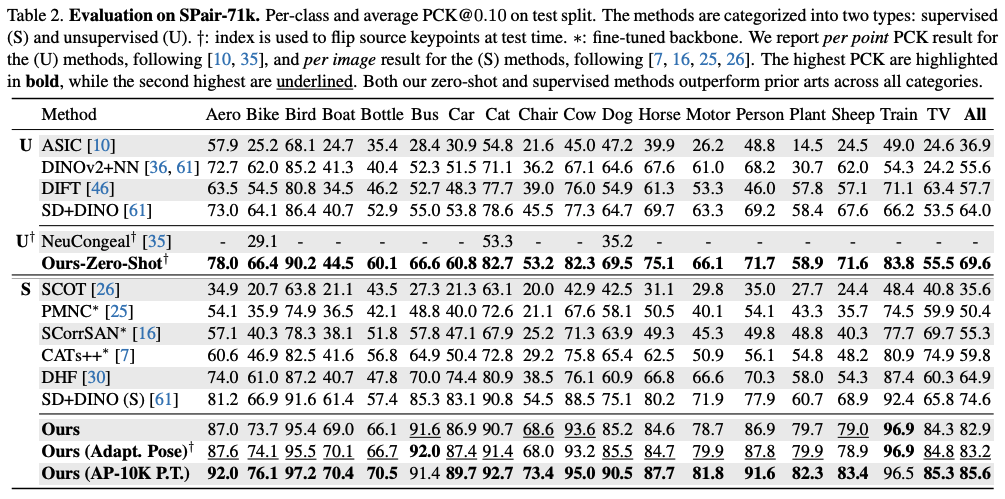
Table 2에서는 각 category 별로의 성능 평가를 보여주고 있다.
기존의 높은 성능이었던 SD+DINO보다 더 높은 성능을 보인다.
Supervised의 경우에는 18개의 모든 category에 대해서 SD+DINO보다 성능이 높았고, 전체 카테고리에 대해 11이나 더 높은 수치를 보였다. 또한 맨 마지막 줄인 AP-10K dataset를 pretrain에 사용했을 때 더 높은 성능을 보였다.
또한 Zero-shot의 경우에도 마찬가지로 SD+DINO보다 더 높은 성능을 보였다.

더 strict thresholds를 가진 PCK@0.05와 PCK@0.01의 경우의 성능표이다. 마찬가지로 SD+DINO와 동일한 raw feature map을 사용했음에도 불구하고 더 좋은 성능을 보였다.
또한 AP-10K dataset의 경우intra-species set에서만 훈련했음에도 C.S.(cross-species), C.F.(cross-family) 에서도 좋은 성능을 보이고 있다. 이는 generalization성능을 잘 보여준다.
Geometry-aware Semantic Correspondence
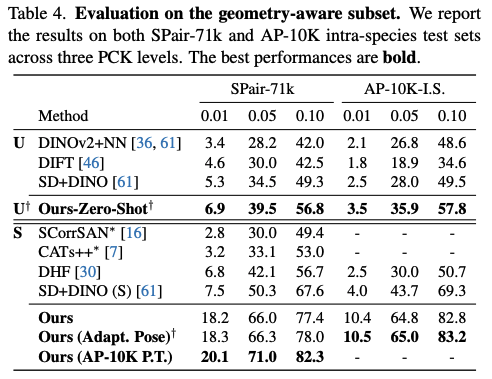
Table 4에서는 Geometry-aware subset에 대한 성능 평가를 진행하였다. Adaptive viewpoint alignment가 선응에 긍정적인 영향을 주었으며, zero-shot 및 supervised 모두에서 좋은 성능을 보였다.
Ablation Studies

Ablation study를 해보았을 때, 각각의 component들이 성능 개선에 도움을 주고 있음을 보이고 있다.
생각보다 Dense Trianing Objective의 성능 향상이 컸고, Perturbation & Dropout의 경우에도 성능 향상이 있었다.
Window Soft Argmax에서는 윈도우 크기에 따라 다른 성능을 보였는데, supervised에서는 15x15, unsupervised에서는 11x11에서 가장 좋은 성능을 보였다. dataset이 다른 것이 아닌데, 왜 학습 방식에 따라서 window 크기가 달라져야하는지가 궁금했다..
4.2. Qualitative Analysis

SD+DINO와 비교한 결과이다. 초록색이 맞은 경우이고, 빨간 석이 matching이 틀린 경우인데, SD+DINO에 비해 Ours가 더 좋은 matching을 보이는 것을 확인 할 수 있다.
그리고 SD+DINO의 경우 특히 geometric ambiguity에서 matching을 잘 찾아내지 못한다는 단점이 있었다.

similarity map을 visualization 해보았을 때, SD+DINO의 경우에는 의자에 대한 match point로 비슷한 appearance를 가진 point에 대해 찾은 것을 확인할 수 있다. 나무 의자에 대해, 나무 재질의 물체에 highlight 된 것을 확인할 수 있다.
SD+DINO의 supervised version의 경우에는 모든 부분에 highlight 된 noisy similarity maps가 관찰되었으며, 이는 sparse tarining으로 인해 생긴 문제라고 보고 있다.
반면에 본 논문에서 제시된 방법으로는 올바르게 의자에 point가 잘 잡힌 것을 확인할 수 있다.
Limitation
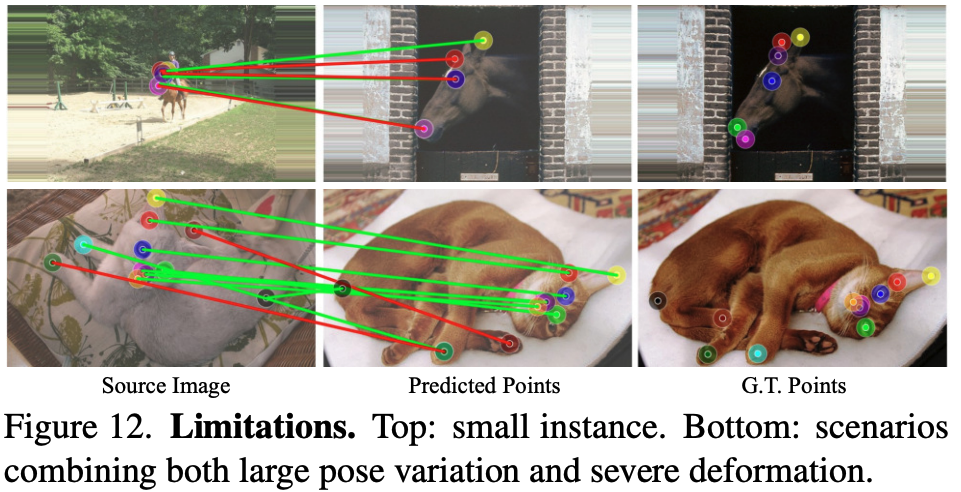
본 논문은 small instance나 심한 deformation이 존재할 경우 성능이 떨어진다는 것을 limitation으로 적어놓았다.
5. Conclusion
본 논문은 semantic correspondence 문제에서 geometry ambiguity를 문제로 삼았으며, 이를 해결하기 위해서 pose-variant augmentation 등 다양한 방법을 제안했으며, 새로운 benchmark 또한 제안하였다.