A Simple Framework for Contrastive Learning of Visual Representations
이 논문은 ICML 2020에 accept된 논문으로, Ting Chen 1 Simon Kornblith 1 Mohammad Norouzi 1 Geoffrey Hinton 1 (Google)에서 나온 논문이다.
1. Motivation
이 논문은 최근에 제시된 contrastive self-sup learning algorithm을 간단한 방식으로 접근한 것이다.
contrastive prediction task가 useful representation을 배우도록 하는 것이다.
이 논문은 아래 세가지를 보였다.
1) composition of data augmentation은 supervise보다 unsup contrastive learning에서 효과가 더 크다는 것을 발견하였다.
2) representation과 constrastive loss 사이에 learnable nonlinear transformation을 도입하면 representation의 품질을 크게 향상시킬 수 있다.
3) contrastive learning은 supervised learning에 비해 larger batch size와 training steps를 적용할 때 더 이점을 얻는다.
2. Method
2.1. The Contrastive Learning Framework
SimCLR는 같은 data를 다르게 augmentation한 뒤, 이 사이를 Maximize agreement를 통해 Representations를 배운다.

이 method는 4가지 주요 components를 따른다.
1)
Figure2 에서 $\widetilde{x_i}$ 와 $\widetilde{x_j}$ 는 같은 example에 대해 random 하게 data augmentation을 진행한 결과로, 이 둘은 positive pair이다.
여기서 three simple augmentation을 진행하는데, 이는 random cropping, random color distortion, 그리고 random Gussian blur이다. 이후에 볼 섹션3에서, random crop과 color distortion을 사용하는 것이 좋은 성능을 얻는데 중요한 것을 알아내었다.
2)
neural network $\textit{base\,encoder}\,f(\cdot )$은 augmented data examples에서 representation vectors를 추출해내며, 여기서는 ResNet을 사용하였다.

3)
small neural network인 $\textit{projection\,head}\,\,g(\cdot)$는 representation을 contrastive loss가 적용되는 space로 맵핑하는 역할을 한다. 여기서는 MLP를 사용하였다.

여기서 시그마는 ReLU non-linearity를 의미한다. 뒤의 섹션4에서 볼 수 있듯이, $h_i$ 보다 $z_i$에서 contrastive loss를 적용하는 것이 더 좋다는 것을 찾아내었다.
4)
contrastive loss function은 contrastive prediction task를 위해서 정의되었다.
주어진 set $\{\widetilde{x}_k\}$ 은 posirivs pair들을 포함하고 있으며, contrastive prediction task는 주어진 $\widetilde{x}_i$에 대해 $\widetilde{x}_j$ 를 $\{\widetilde{x}_k\}_{k\neq i}$ 에서 식별하는 것을 목표로 한다.
본 논문에서, random하게 minibatch of N examples를 샘플링하고, contrastive prediction task 를 정의한다.
각 pair는 augmented example을 말하는 것이기 때문에, 총 2N data points가 존재한다.
negative examples는 explicitly하게 샘플링하지 않고, 주어진 positive pair가 아닌 다른 2(N-1)개의 augment된 examples를 negative examples로 삼는다.

sim은 l2 normalize된 u 와 v의 dot product를 의미한다.
이를 바탕으로 positive pair인 (i,j)에 대한 loss fuction은 아래와 같이 정의된다.

최종적인 loss는 (i,j)와 (j,i)에 대해 적용되며, 이 Loss를 NT-Xent로 부르기로 한다.

algorithm은 위와 같다.
2.2 Training with Large Batch Size
method를 간단하게 만들기 위해서 memory bank를 이용하지 않았다. 대신에 training batch size N을 256에서 8192로 다양하게 실험을 해보았다. batch size가 8192일 때 negative examples는 16382개가 된다.
큰 batch size로 학습할 때 SGD/Momentum with linear learning rate scaling을 사용하는 경우에는 불안정할 수 있기 때문에, 안정화시키기 위해서 LARS optimizer를 사용하였다.
Global BN
BN의 mean과 variance는 device마다 local하게 축적되게 된다. 본 논문의 contrastive learning에서 positive pair들은 같은 device에서 계산이 되고, 이는 모델이 local informatino leakage로 단순히 prediction accuracy를 올릴 수 있다. 이는 representation을 향상시키지는 않고 발생하는 일이기 때문에 이를 막아야한다.
따라서, 이를 해결하기 위해서 aggregating BN mean과 variance를 모든 devices에 대해서 축적시켰다.
2.3 Evaluation Protocol
Dataset and Metrics
ImageNet ILSVRC-2012 dataset을 이용했다. transfer learning을 위해서 pretrained results를 큰 dataset에 대해서도 test하였다.
learned representation에 대해 평가하기 위해 linear evaluateion protocol을 따랐따. 이는 linear classifier가 frozen base network 위에서 학습이 되고, test accuracy는 representation quality를 위한 proxy로 사용하는 것을 말한다.
이외에도 semi-supervised와 transfer learning의 SoTA와 비교분석하였다.
Default setting
data augmentation으로는 random crop과 resize with random flip, color distortions, and Gaussian blur 를 사용하였다.
ResNet-50을 base encoder network로 사용하였고, 2-layer MLP projection head를 representation 을 128-dim latent space로 맵핑하기 위해서 사용하였따.
앞서 말한 것과 같이, NT-Xent를 Loss로 사용하고 learning rate는 4.8으로 LARS를 이용해서 optimize하였다. 100 epochs에 대해 4096 batch size로 학습하였다.
3. Data Augmentation for Contrastive Representation Learning
Data augmentation defines predictive tasks
data augmentation은 supervised, unsupervised representation learning에 모두 잘 사용되는 기법이지만, contrastive prediction task를 정의하는 체계적인 방법으로는 간주되지 않았다.
기존의 존재하는 접근법들은 architecture를 바꾸는 방향으로 contrastive prediction task를 정의하였다. 본 논문에서는 간단한 random cropping with resizing을 통해서 기존의 복잡한 방법들을 피할 수 있다고 하였다.
3.1 Composition of data augmentation operations is crucial for learning good representations

Figure 4는 이 논문에서 사용한 data augmentation들을 나타낸 것이다.
각각의 data augmentations와 augmentation composition의 중요성을 분석해보았다.

그러나 ImageNet은 다른 size의 이미지를 포함하고 있다. 따라서 항상 crop과 resize를 적용해야한다. 이는 직접적인 비교를 어렵게 만들기 때문에, 항상 random crop과 resize를 적용하고, target transformation을 한 branch에만 적용하였다.
즉 다른 한 branch는 identity로 남겨두는 것이다.
Figure 5를 살펴보면, single transformation은 좋은 representation을 학습하기에 충분하지 않다는 것을 알아내었다.
random cropping과 random color distortion을 함께 사용했을 때 가장 좋은 성능을 보였다.
저자들은 random cropping을 사용할 때의 문제점은 이미지 패치들이 유사한 색상 분포를 공유하는 것이라고 추측하였다.
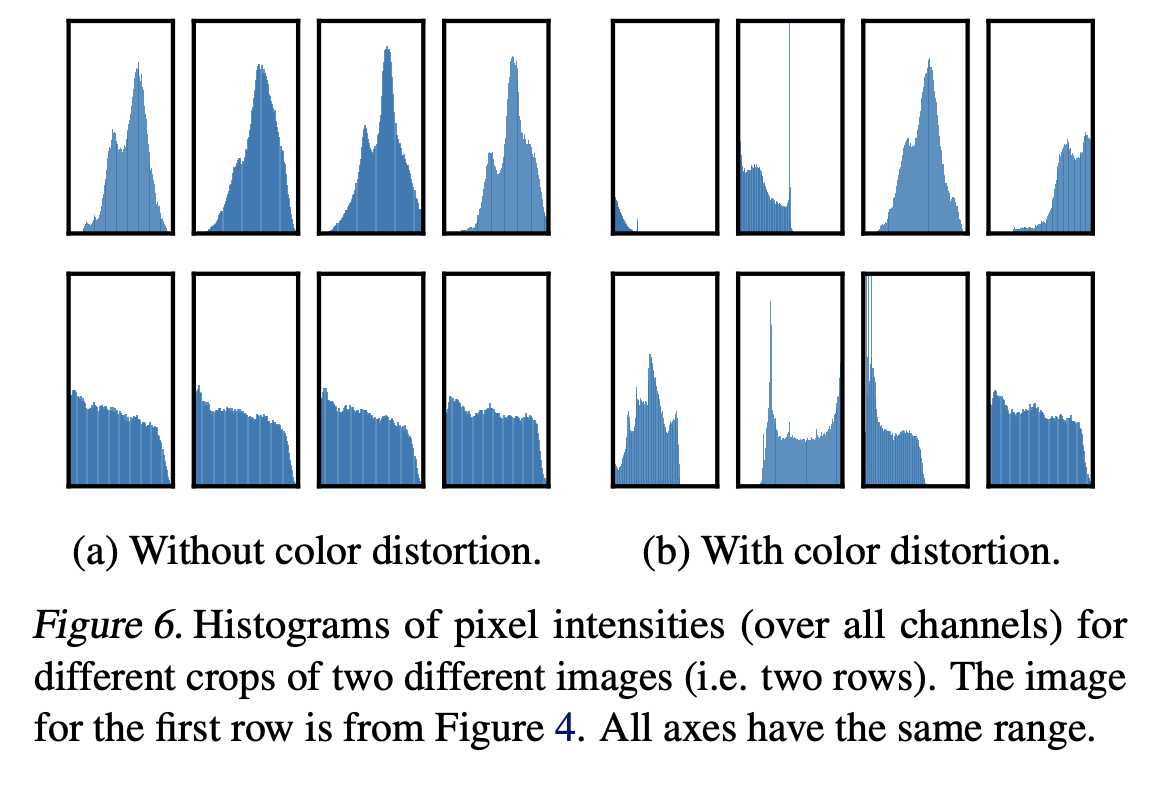
실제로 color histogram을 그려보았을 때 color histogram 만으로 이미지를 구분할 수 있다는 것을 알 수 있다. (Figure 6 (b))
따라서 network는 이 shorcut을 이용하여 prediction을 적용할 수 있다. 따라서 generalizable features를 학습하기 위해서는 color distortion을 함께 사용하는 것이 중요하다는 것을 알 수 있다.
3.2 Contrastive learning needs stronger
color augmentation의 중요성을 증명하기 위해서, strength of color augmentation을 적용해보았다.
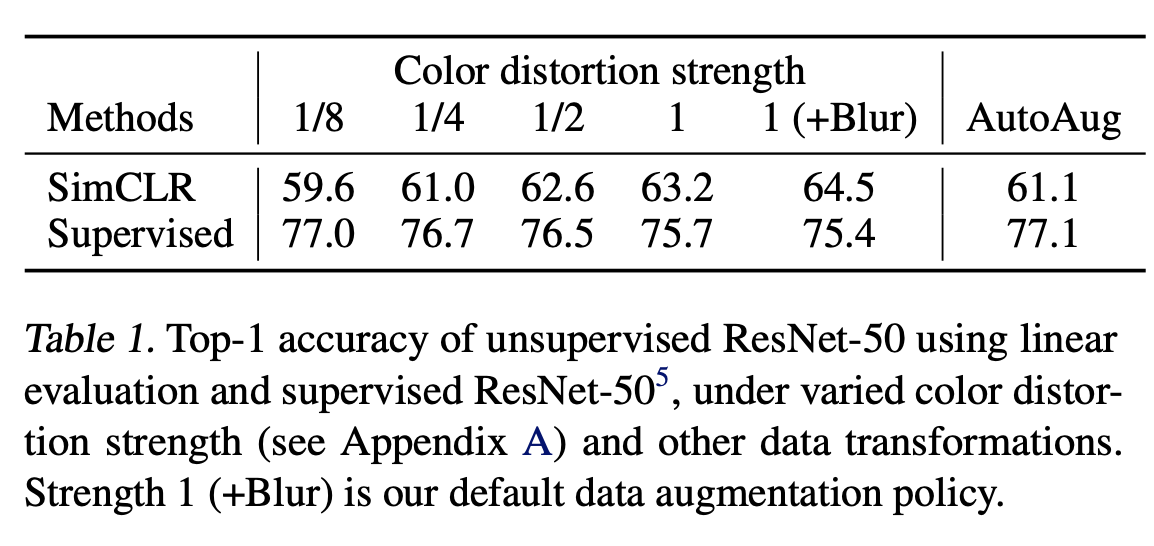
Stronger color augmentation은 unsupervised model에서 학습한 경우 linear evlaution에서 높은 성능 향상을 보였다.
추가적으로 정교한 augmentation policy가 적용된 AutoAugment를 적용했을 때 (77.1), supervised learning의 경우 단순한 cropping + (stronger) color distortion보다 더 좋은 성능은 보이지 않았다.
즉 augmentation을 supervised model에 적용했을 때, stronger color augmentation은 성능에 악영향을 준다는 것을 알아내었다.
따라서 이 실험은 unsupervised contrastive learning이 stronger (color) data augmentation에 더 좋은 영향을 받는 다는 것을 알아내었다. (supervised learning 보다)
4. Architectures for Encoder and Head
4.1 Unsupervised contrastive learning benefits (more) from bigger models
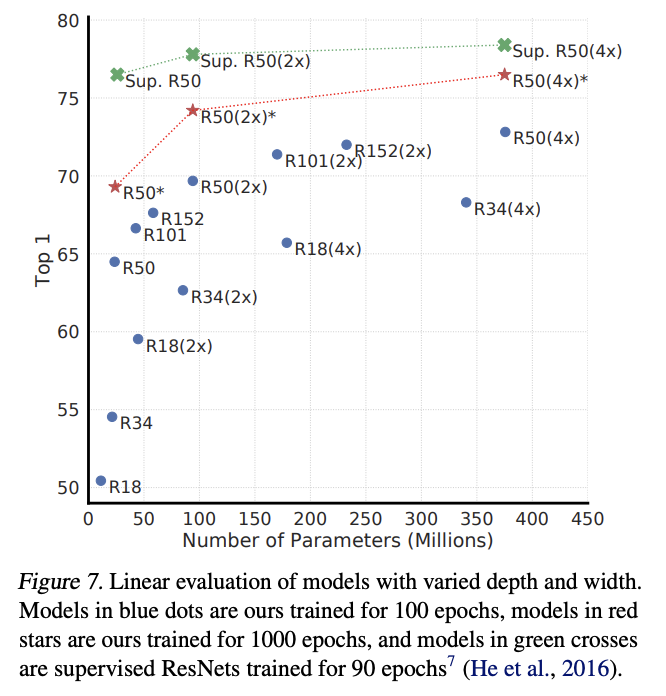
Figure 7은 increasing depth and width는 둘 다 성능을 향상시킨다는 것을 보여주고 있다.
supervised model과 linear classifiers trained on unsup models의 성능 차이는 model 사이즈가 증가할수록 줄어드는 것을 알 수 있다. 이를 통해 unsupervised learning은 supervised에 비해 bigger models에서 더 큰 benefits를 얻을 수 있다는 것을 추측할 수 있다.
4.2 A nonlinear projection head improves the representation quality of the layer before it
projection head의 중요성을 분석해보았다.
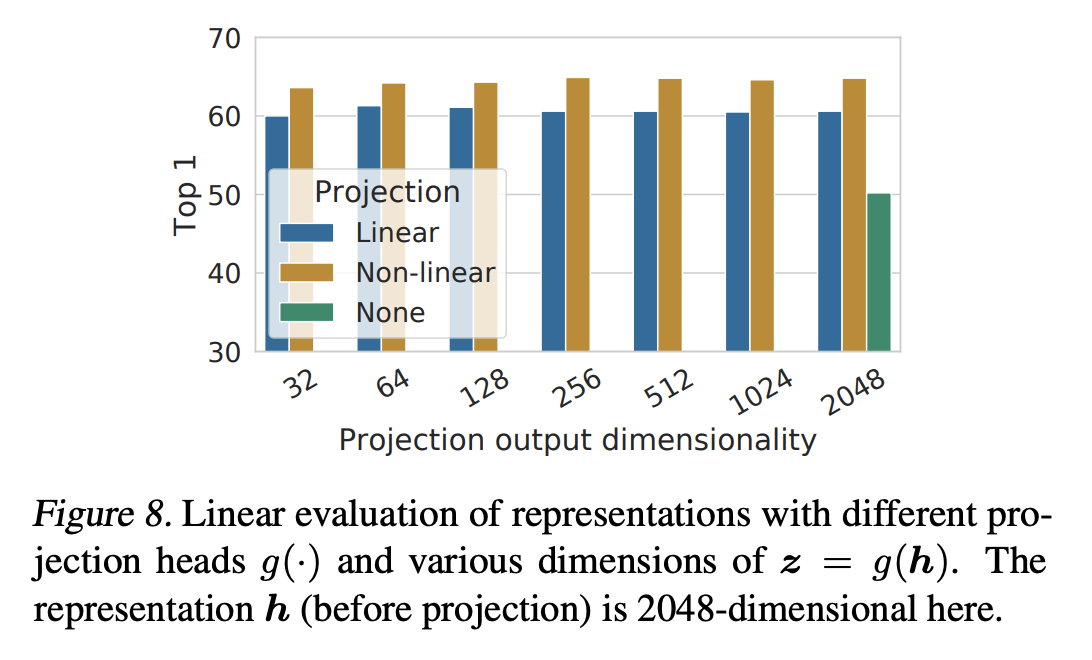
linear evaluation results를 세가지 다른 head architecture를 적용했을 때 분석해보았다.
identity mapping, linear projection, default nonlinear projection with one additional hidden layer (ReLU) 이다.
non-linear projection이 no projection이나, linear projection보다 더 좋은 성능을 보인 것을 알 수 있다.
non-linear projection이 사용될 때, projection head 이전 계층인 h 는 이후 계층인 z=g(h) 보다 더 좋은 representation을 나타내는 것을 알 수 있으며, 이는 projection head 이전의 hidden layer가 이후의 layer보다 더 좋은 representation이라는 것을 알려준다.
논문에서는 위와 같은 이유를 contrastive loss에 의해서 생긴 정보의 손실때문이라고 보고 있다. 특히 z는 데이터가 변환되는 것에 invariant 하도록 학습되기 때문에, g는 downstream task에 유용할 수 있는 정보를 제거할 수 있다. 따라서 h 가 더 좋은 representation인 것이다.
이를 검증하기 위해서 pretrain동안에 적용된 transformation을 예측하도록 h, g(h)를 사용하여 실험하였다.
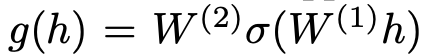
위와 같이 g(h)를 설정하였다.
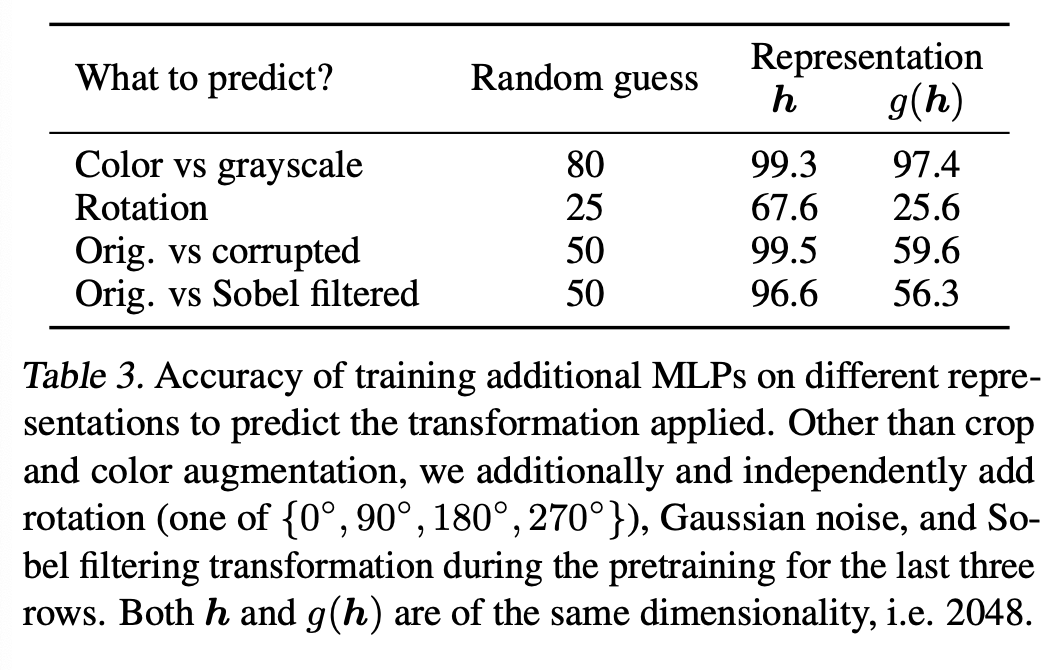
Table 3를 통해 h가 적용된 transformation에 대해 더 많은 정보를 가지고 있다는 것을 알 수 있다.
5. Loss Functions and Batch Size
5.1 Normalized cross entropy loss with adjustable temperature works better than alternatives
이 섹션에서는 NT-Xent los를 다른 contrastive loss와 비교하였다.

gradient 분석을 통해서 다음과 같은 것을 알아내었다.
1) l2 normalization와 temerature가 다른 examples에 대해서 효과적으로 가중치하고, 적절한 temperature가 hard negatives들로부터 학습하는데 도움이 된다는 것을 알아내었다.
2) cross-entropy와는 달리 다른 함수들은 상대적인 negatives hardness에 따라 가중치 하지 않는다. 따라서 이러한 loss function들에 대해서 semi-hard negative mining을 적용해야한다.
공정한 비교를 위해서 모든 loss에 l2 normalization을 적용하였다.

결과를 보면 negatie mining이 도움이 되는 것은 맞지만, NT-Xent loss가 가장 좋은 성능을 보였다.
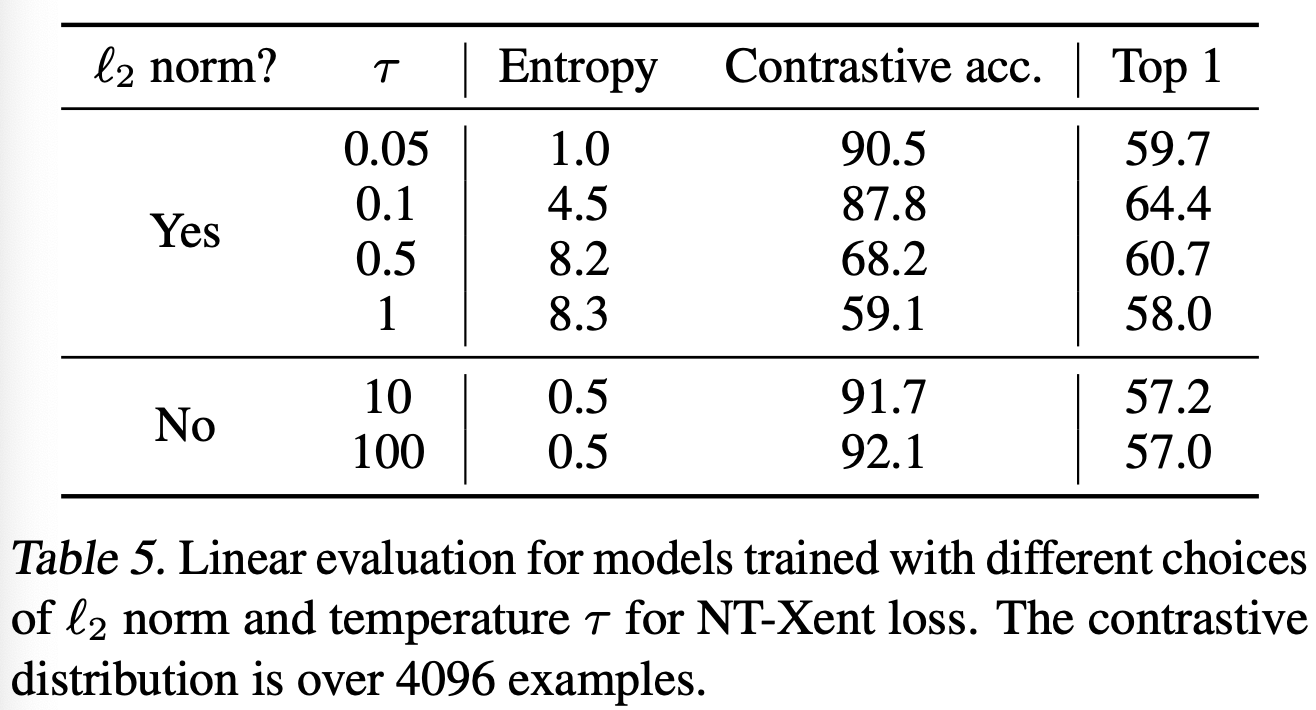
추가적으로 l2 normalization과 temperature의 중요성을 살펴보는 실험을 해보았다. Table 5를 보면, normalization이나, 적절한 temeperature scaling을 하지 않은 경우 성능이 매우 하락한 것을 알 수 있다.
l2 normalization을 하지 않은 경우, contrastive task accuracy는 향상되었지만, representation 학습은 잘 이루어지지 않은 것을 알 수 있다.
5.2. Contrastive learning benefits (more) from larger batch sizes and longer training
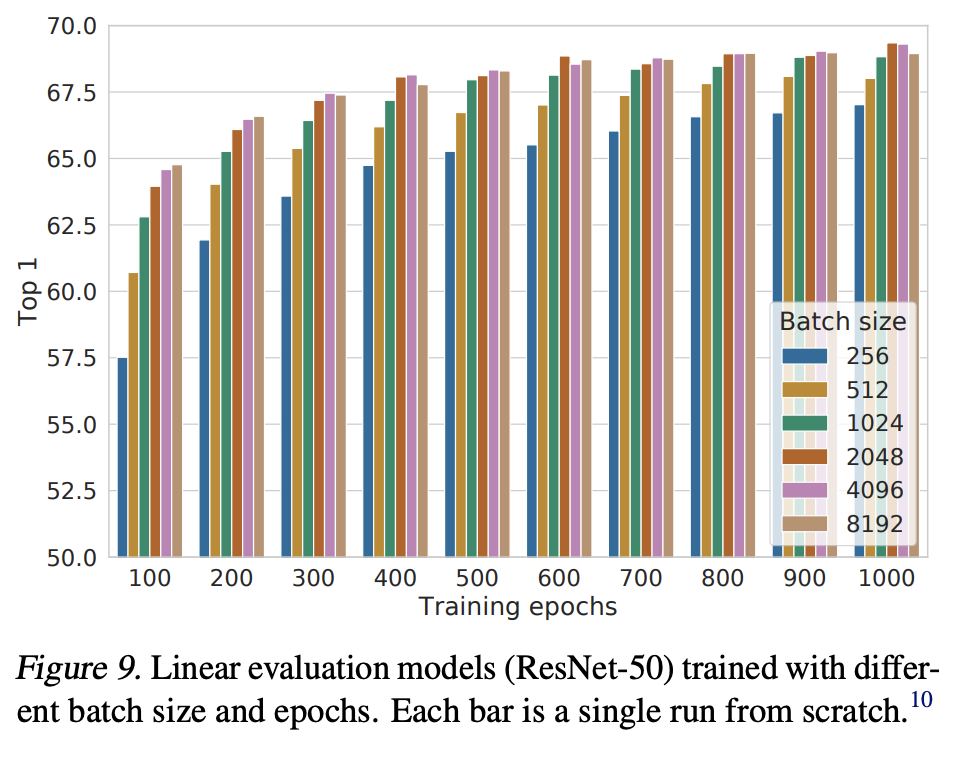
batch size를 다르게 했을 때, 작은 경우보다 batch size가 더 클 때 성능이 더 향상된 것을 알 수 있다.
epoch를 더 많이 학습할수록 다른 batch size에 대한 영향은 줄어드는 것을 알 수 있다.
6. Comparison with State-of-the-art
Linear evaluation
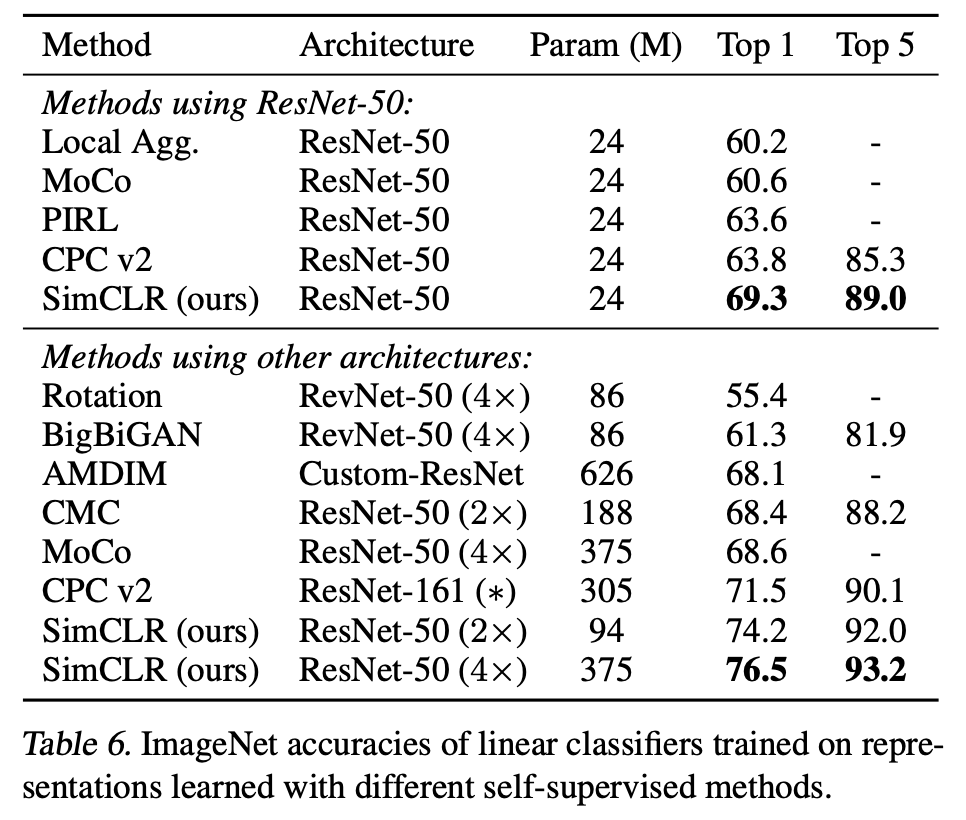
실험 결과, simCLR는 이전의 specifically designed architecture와 비교했을 때 더 좋은 결과를 얻을 것을 알 수 있다.
Semi-supervised learning
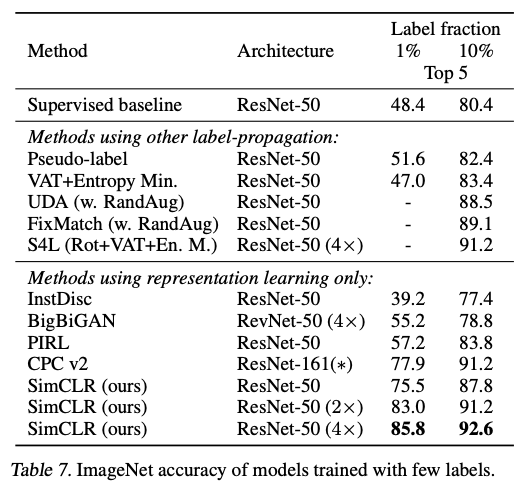
ILSVRC-12 dataset을 클래스별로 균등하게 샘플링하고 semi-supervised learning 과 비교를 해보았다.
Table 7를 보면, 1%, 10%의 label을 사용할 때 모두 기존의 기술들보다 좋은 성능을 보이는 것을 알 수 있다.
Transfer Learning
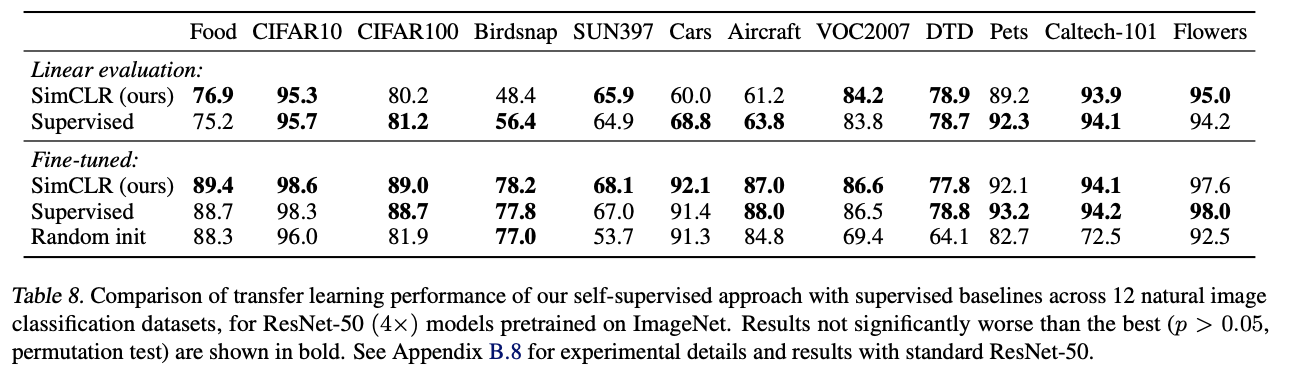
12개의 natural image dataset에서 transfer learning performance를 확인해보았다.
Table 8을 통해, 논문에서 제시한 방법은 fine-tuning했을 때, 5개의 데이터셋에 대해서
Supervised learning 수준을 뛰어넘은 것을 알 수 있다.
7. Conclusion
본 논문에서는 contrastive visual representation learning을 위한 간단한 framework를 제시하였다. 이를 통해서 self-sup, semi-sup, transfer learning의 이전 방법들보다 더 높은 성능 향상을 이루었다.